
1. Large Language Modelとは?
Open AI ChatGPT、Google Gemini、Microsoft Copilot などのスマートテクノロジー製品は、近年さまざまな分野で広く使用されています。
この記事では、これらの製品のバックボーンテクノロジである大規模言語モデル(LLM :Large Language Model) の概要(概念、用語、適用時の使用方法等)について紹介します。
LLM の性質を理解するため、図 1 で人工知能分野(Artificial Intelligence)の全体像を見てみましょう。
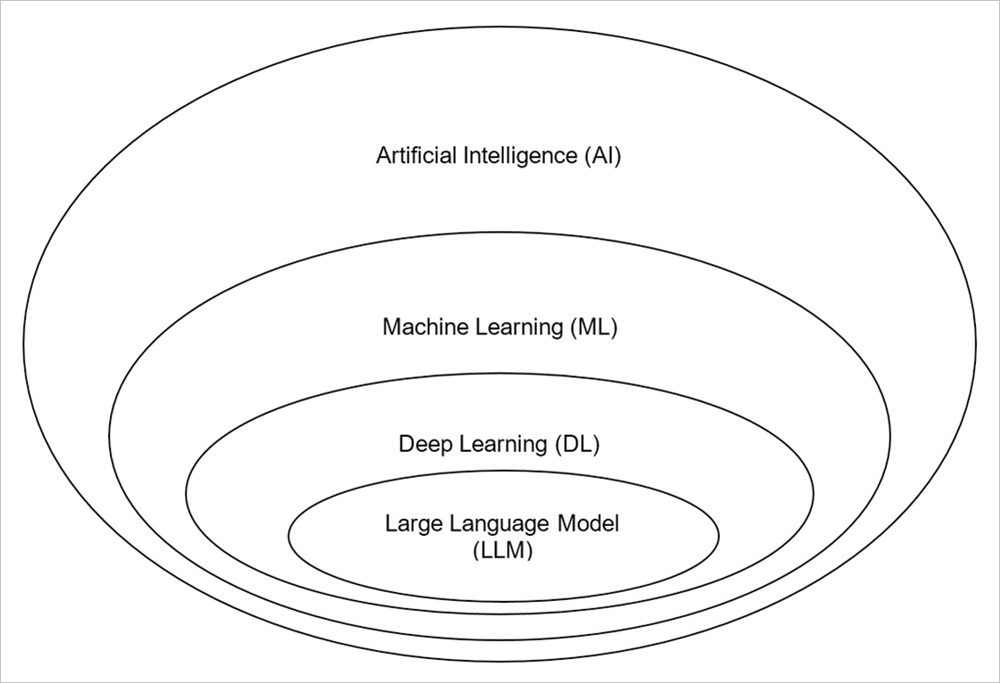
図1:人工知能における大規模言語モデル
1.1. Artificial Intelligence
Artificial Intelligence (AI) - 人工知能は、コンピューターが人間と同じように認識・理解を行い、タスクをインテリジェントに実行できるようにするテクノロジーの開発に焦点を当てたコンピューターサイエンスの一分野です[1]。 AIができることは、画像認識(Computer Vision)、自然言語処理 (NLP:Natural Language Processing)、ロボット工学(robotics)などになります。
図2: テキスト内のエンティティを識別して抽出するための AI 適用(NLP)
1.2. Machine Learning
Machine Learning (ML) - 機械学習は、AIの一分野であり、従来のプログラミングと異なり、コンピューターを使用して大量データの分析・学習を行います。実運用時には、コンピューターが学習済みデータに基づいて決定を行います[2]。MLでの典型的な手法として、Regression(回帰)、Classification(分類)、Clustering(クラスタリング)などがあります。
コンピューターが信頼性のある大量データに基づいてトレーニングされていれば、より精度の高い結果を出すことができます。
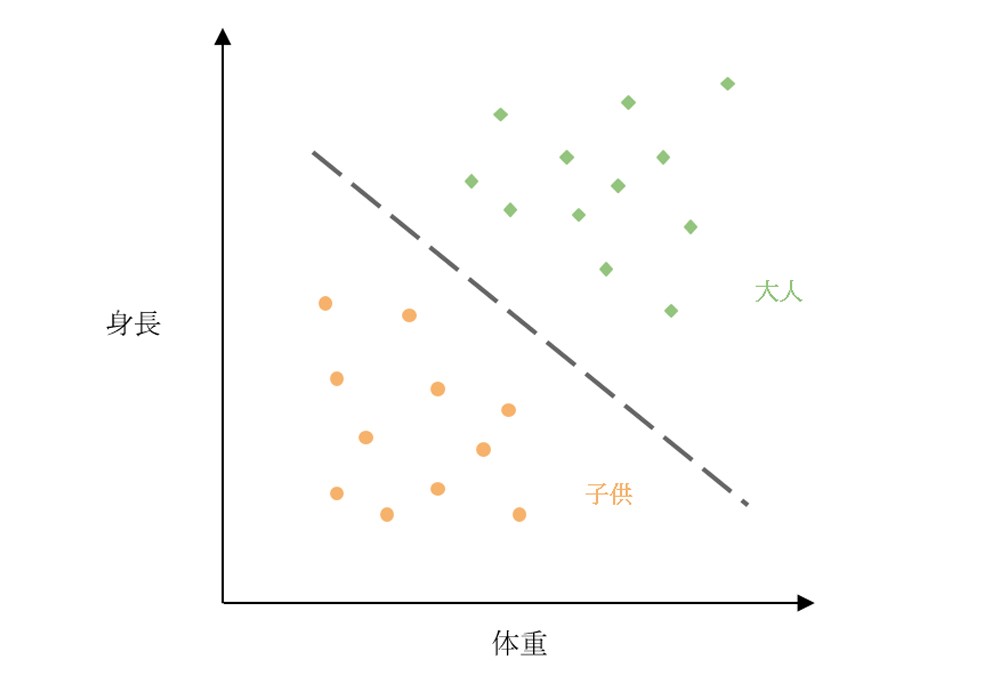
図3: 身長および体重による大人および子供の分類(Classification)
1.3. Deep Learning
Deep Learning (DL) - ディープラーニングは、MLの研究分野の1つであり、人間の脳の
仕組みからヒントを得たニューラルネットワークアーキテクチャ(neural network)で
構築されています。
MLにおいては、コンピューターの学習データに対し人間による事前の特徴抽出 (Feature Extraction)が必要である一方で、ディープラーニングにおいては、データから特徴を自動認識することにより、人間への依存を減らすことができます [3]。
そのため、ディープラーニングを効果的に実行するためには大量のデータが必要になります。
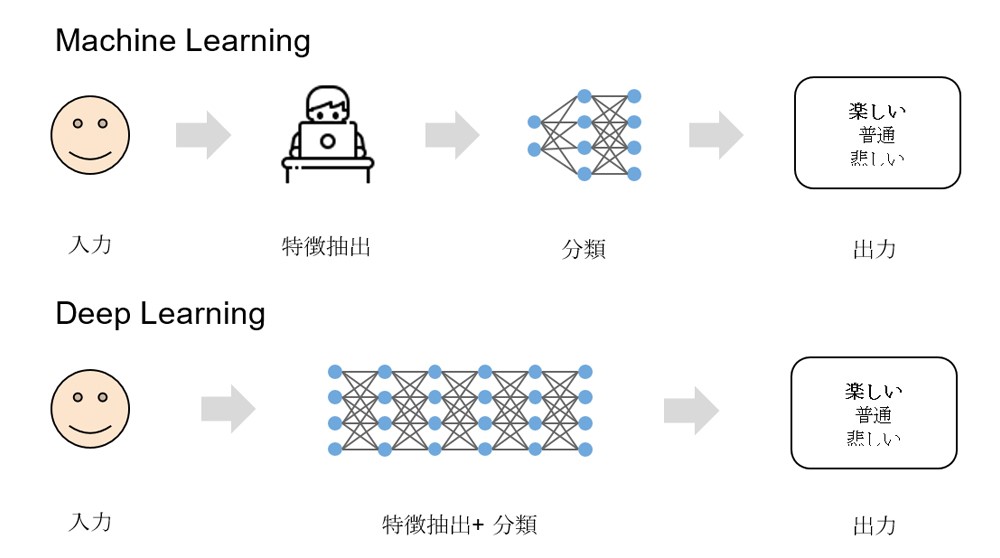
図4: Machine LearningおよびDeep Learningの違い
1.4. Large Language Model
LLMを理解するには、まずModel(モデル)およびLanguage Model(言語モデル)の定義について学びましょう。
- モデルまたはAIモデルは、インテリジェントなプログラムであり、事前にトレーニング・開発されたタスクを実行するために使用されます [4] 。
- Language Modelは、インテリジェントなプログラムであり、自然言語処理 (NLP) タスクで使用されます。文章の構造、文法、意味を理解することができ、次の単語の予測、テキストの翻訳・要約もできます [5] 。
LLMは、膨大な量のテキストデータでトレーニングされた非常に大規模なDLモデルです。これは、一種の生成AI(Generative AI)であり、人間との自然言語での直接対話において文章内の単語の予測、理解、言語タスク実行、質問への回答の自動生成が可能です[6] 。
LLM は次のようなタスクを実行することができます。
- チャットボット、知識ベースでの質問・回答
- テキストの作成・要約
- 翻訳サポート
- テキスト分類
- 感情分析
- 検索支援ツール
- 異常検出
また、LLMは多くの分野で適用されています。
- ソフトウェア開発: コード・データ作成サポート
- 医療:遺伝子研究、処方箋作成サポート
- 財務: 市場分析、レポート作成
- カスタマーケア: チャットボット、製品マーケティングサポート
- 採用: 候補者スクリーニング・評価
2. LLMの用語
“Meta社からLlama 3.1 405Bモデル (4,050億パラメータ) がリリースされました”
“ChatGPTのGPTとは何ですか?”
“OpenAIは最大 128,000トークンをサポートするGPT-4-turboモデルを発表しました”
LLMでの一般的な用語を理解しましょう。
2.1. Parameter
上で述べたように、LLMは大規模なDLモデルであり、内部に非常に大規模で複雑なニューラルネットワークが含まれています。Parameterは、このネットワーク内のニューロン間のリンクとしてみなされ、数値形式で表されています。モデルがトレーニングされた時に、これらの数値 (リンク) は、学習データに適応して変化します。パラメーターの数が多ければ多いほどモデルは大きくなり、現在ではほとんどのLLMは最大 10億個(Bと略されます)のパラメーターを持っています [7] 。
下図で、毎年モデルパラメータの数が増えていることを示します。
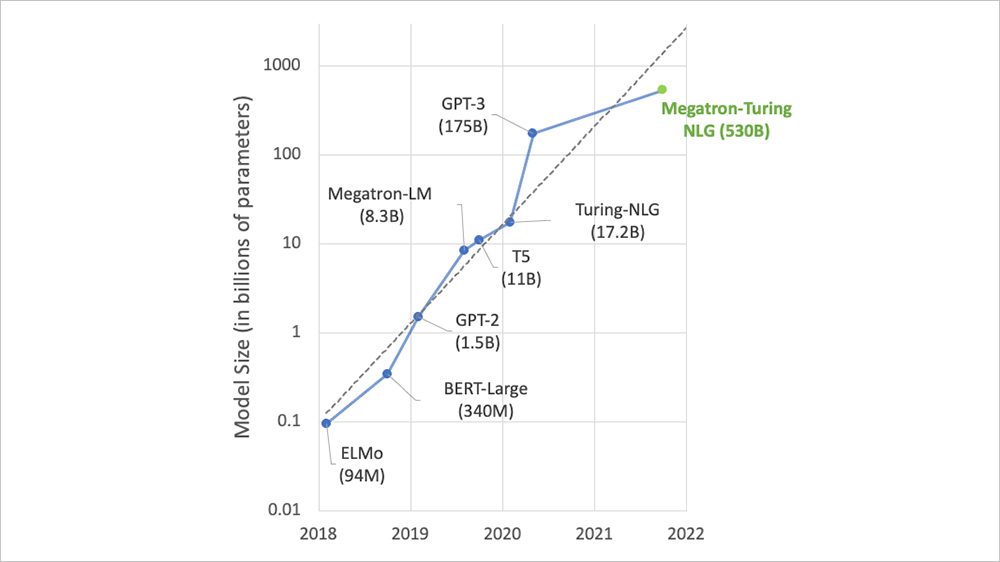
図5: LLMパラメータ数の推移
2.2. Foundation model
モデルがある程度までトレーニングされると、そこで一旦停止され、Foundation Model(基盤モデル) (Base Model(ベースモデル)またはPre-trained Model(事前トレーニング済モデル)とも呼ばれる) として確定されます。その時点でパラメータが固定されていることも意味します[8] 。たとえば、gemma2 は Google により開発されたFoundation Modelです。
Foundation Modelは実際に適用でき特定業務の追加トレーニングもできます。
(Fine-tuning―微調整)
Foundation Modelは新卒者のように、大学で得られる知識(データ)が卒業までの期間で蓄積(トレーニング)され、企業はこの学生を雇用することができます(直接使用)が、この学生は実務経験が無いため、社内トレーニング、業務プロセストレーニング、業務スキル向上などを行うことになります(Fine-tuning)。
ここで、ChatGPT の「GPT」の意味を次のように説明することができます。
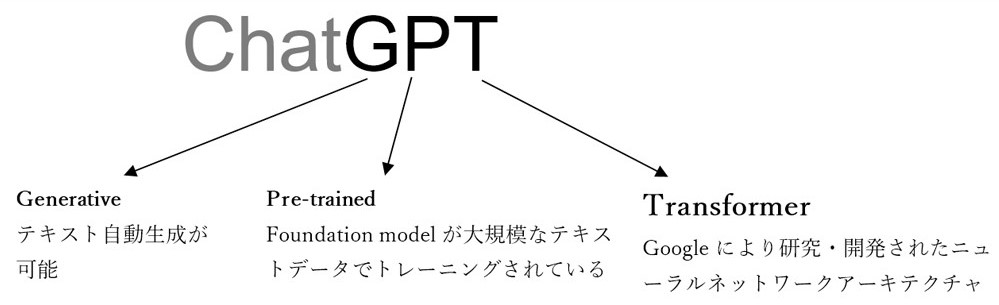
図6: ChatGPT における「GPT」の意味
2.3. Token & tokenization
Token(トークン)とは、言語や文字種類ごとにテキストから分離された単語、文字グループや語句のことです。トレーニング時に、LLMはこれらのトークンの意味の関係性を分析して理解することができます。そして、使用時には、LLM は入力テキストに基づいてトークン文字列を自動的に生成することができます [9] 。

図7: 文内のトークン(トークンの長さを色を変えて示しています)
LLMのモデルごとに、入力から受け取るトークンの量と、自動的に生成できるトークンの数に制限があります。
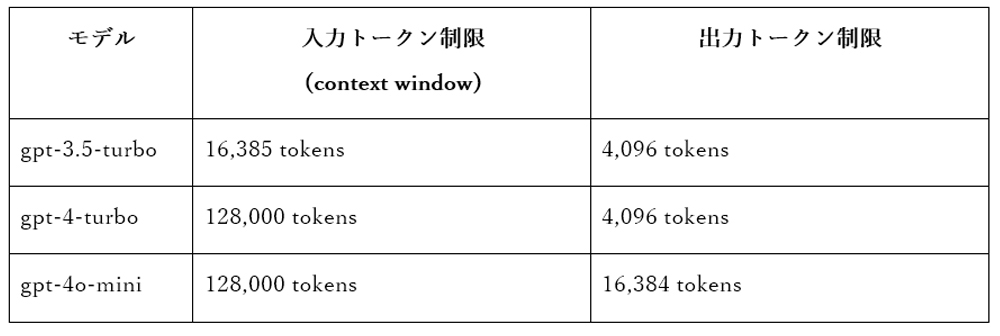
表1:モデルごとの入力・出力トークンの制限
参考元: https://platform.openai.com/docs/models
Tokenization(トークン化)には、入力テキストからLLMが理解できる数値への変換、出力結果の数値から人間が理解できるテキストへの変換が含まれます。これらの2つの処理は、
エンコードおよびデコードと呼ばれます[10] 。
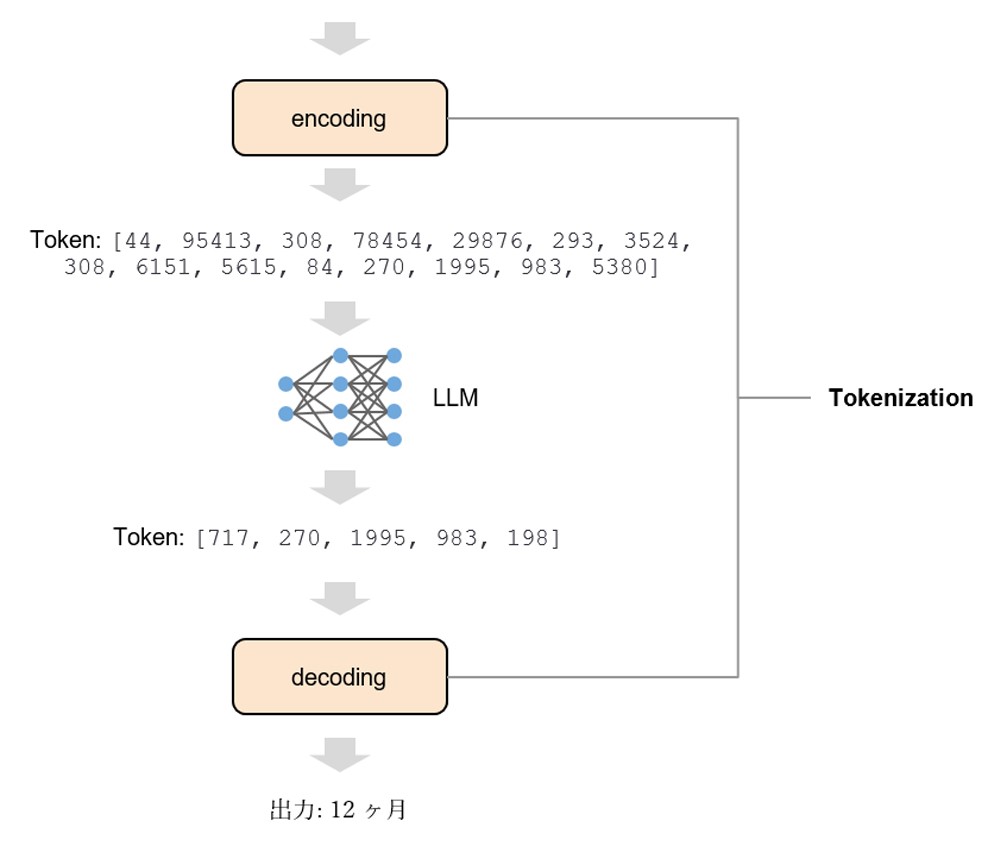
図 8: LLM のTokenization
LLM ごとに、異なるTokenization方法があります。これは人間のように、同じ問題でもさまざまな方法で認識、思考、決定を行うということです。
2.4. Hallucination
Hallucination(幻覚)とは、LLMが実際とは異なる結果を出す現象であり、トレーニングされたデータの範囲外となるテキストを自動的に生成しようとしたときに起こります。実システムへのLLM適用時に、最終的な製品の正確性および信頼性を確保するためにはこの問題に対し注意を払う必要があります [11] 。
たとえば、2021年以前のデータでトレーニングされたLLMが、2024年に起きたイベントに関する質問に対し回答しようとしたときなどです。
LLMでのHallucination現象を回避するため、temperature、top_p、top_kや logit_biasなどのモデルパラメーターを使用することができます。この中で、temperatureパラメータは基本的なパラメータであり、LLMのテキスト自動生成方法への干渉によく使用されます。
たとえば、OpenAIモデルの場合、temperatureの価値領域は0から2です。値が2に近いほど、出力はよりランダムで多様なものになり、コンテンツクリエーションに適している一方で、0に近いほど、出力は学習データに基づいた確定的なものになり、正確さを要する知識の質問回答に適しています [12] 。
3. LLMの利用方法
LLMを実際に応用するためには、複雑さのレベルや開発・使用コストに応じて、さまざまな利用方法があります。この記事では、以下の図に示されている4つの方法について説明します。
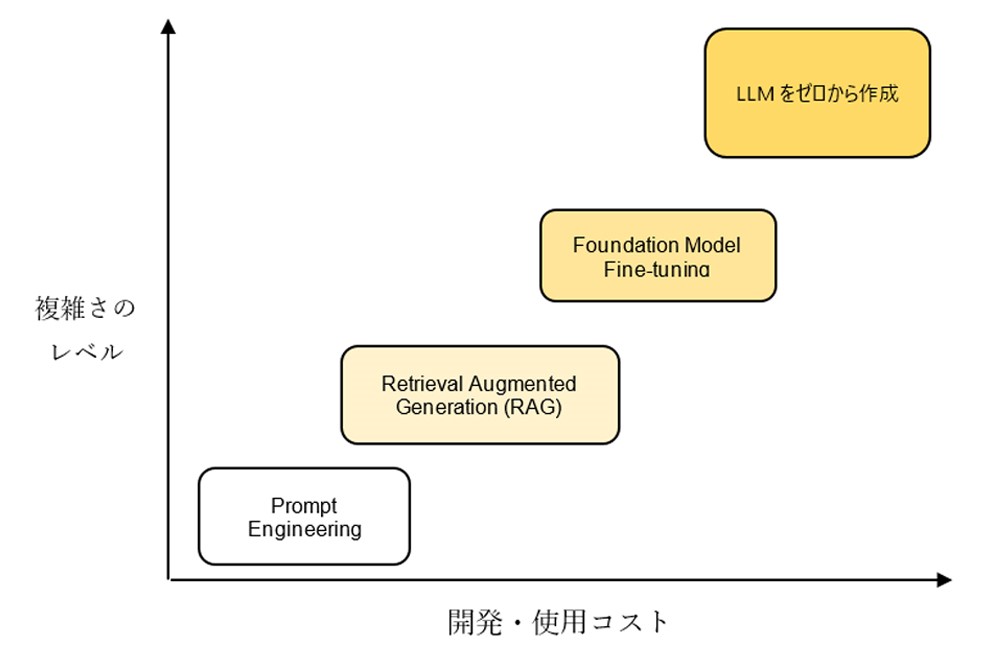
図 9: 複雑さのレベル、開発コスト、および使用コストに基づくLLMの利用方法を示した図
参考文章: https://notebooks.databricks.com/demos/llm-rag-chatbot/index.html
3.1. プロンプトエンジニアリング
プロンプトエンジニアリングは、最も基本的で一般的な方法です。最も簡単な例は、ChatGPTを使って質問をし、それに対して答えを得ることです。期待する答えを得るために、適切な質問をする技術を「プロンプトエンジニアリング」と呼びます【13】。
プロンプトエンジニアリングには多くの手法があり、いくつかの代表的な例として以下のものがあります【14】。
- 1つの質問だけをして答えを得る(Zero-shot prompting)。
- 実行すべき手順を含む質問をして答えを得る(Few-shot prompting)。
- 複数の質問と模範解答を設定し、最終的な答えを導くためにLLMに推論させる(Chain-of-thought Prompting)。
3.2. Retrieval Augmented Generation(検索拡張生成)
Retrieval Augmented Generation (RAG)は LLMと未学習データを組み合わせて利用する方法です。ユーザは質問を出す前、コンテキストを提供しそのコンテキストに基づき質問を行うので、LLMにそのコンテキストに適した回答を生成させます。
RAGを使用する場合は、LLM [15]モデルの再トレーニングに費用を費やす必要はありません。
たとえば、公開試験を受ける学生 (LLM) は、教材の使用を許可されます。学生は、質問(入力)に基づいて文章(コンテキスト)を調べて適切な回答(出力)を出すような形です。
中小企業にとって、この方法は効果的かつ利用しやすいと考えられています。
3.3. Foundation Model Fine-tuning
Foundation Model Fine-tuning(ファウンデーションモデルのファインチューニング)は、既存のLLMを特定のデータセットで訓練する方法です。この方法は、特定の業務に対する深い理解を高めたい場合によく使用されます。訓練後のLLMは、そのデータに対して専門的で特化したものになります【16】。
しかし、この方法を実施するためにはデータとハードウェアインフラの両方を満たす必要があります。
- データ:ボリューム多い・高品質かつ信頼度が高い
- ハードウェアインフラ:モデル訓練に対応できる十分な性能をもつハードウェアが必要です。つまり、インフラの性能はモデルの規模に比例する必要性があります。
3.4. LLMをゼロから作成する方法
ゼロからLLMを作成する方法は、最も複雑でコストがかかる方法です。
Fine-tuningとは異なり、Fine-tuningではすでに訓練されたファウンデーションモデルに追加のデータを拡張するだけですが、ゼロからLLMを作成するには、はるかに大量のデータ、強力なハードウェアインフラ、モデル構築に関する技術的な知識、そして多くの他の要件が必要です【17】。
以下はMetaによって開発されたLlama3モデルのコストに関するいくつかの具体例です。
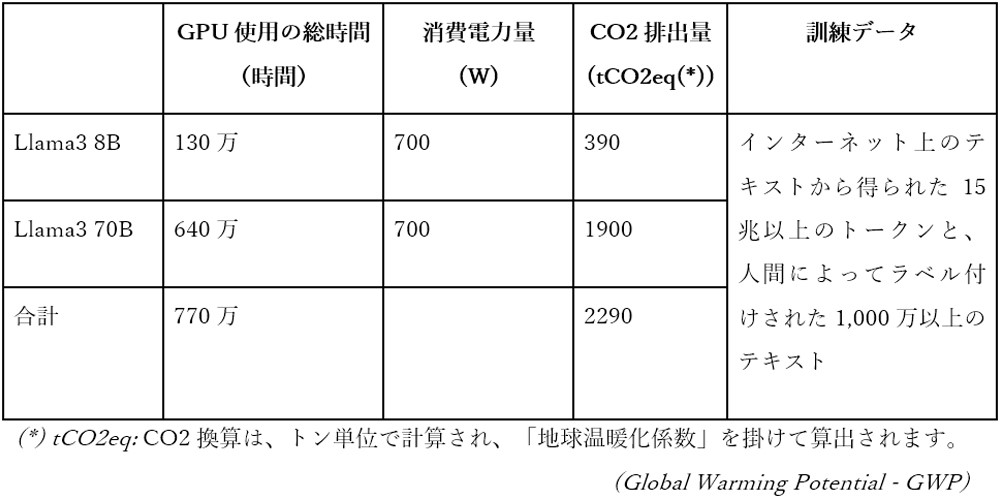
表 2: Llama3 モデルの作成にかかるコストについて説明
参考元: https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
参考元:
[1] AWS. (2024). What is Artificial Intelligence?. https://aws.amazon.com/what-is/artificial-intelligence/.
[2] AWS. (2024). What is Machine Learning?. https://aws.amazon.com/what-is/machine-learning.
[3] Google. (2024). What's the difference between deep learning, machine learning, and artificial intelligence?. https://cloud.google.com/discover/deep-learning-vs-machine-learning.
[4] IBM. (2024). What Is an AI Model?. https://www.ibm.com/topics/ai-model.
[5] H2O. (2024). Language Modeling https://h2o.ai/wiki/language-modeling/.
[6] AWS. (2024). What are Large Language Models?. https://aws.amazon.com/what-is/large-language-model/.
[7] Andreas Stöffelbauer. (2023). How Large Language Models Work. https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f.
[8] Tensor. (2023). Glossary of LLM and Generative AI. https://medium.com/@shuchaobi/glossary-of-llm-and-generative-ai-b3111da41da7.
[9] Microsoft. (2024). Understanding tokens. https://learn.microsoft.com/en-us/dotnet/ai/conceptual/understanding-tokens.
[10] MistralAI. (2024). Tokenization. https://docs.mistral.ai/guides/tokenization/.
[11] Deval Shah. (2023). The Beginner’s Guide to Hallucinations in Large Language Models. https://www.lakera.ai/blog/guide-to-hallucinations-in-large-language-models.
[12] OpenAI. (2024). API Reference. https://platform.openai.com/docs/api-reference/chat/create.
[13] AWS. (2024). What is Prompt Engineering?. https://aws.amazon.com/what-is/prompt-engineering/.
[14] Pranab Sahoo et al. (2024). A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications. https://arxiv.org/pdf/2402.07927.
[15] Databricks. (2024). What Is Retrieval Augmented Generation, or RAG?. https://www.databricks.com/glossary/retrieval-augmented-generation-rag.
[16] Turing. (2024). Fine-Tuning LLMs: Overview, Methods, and Best Practices. https://www.turing.com/resources/finetuning-large-language-models.
[17] Anil Prasad. (2023). Understanding cost, options and Technical steps to build LLM from scratch. https://medium.com/@anilAmbharii/understanding-cost-options-and-technical-steps-to-build-llm-from-scratch-d68cb9ba7bd9.
